Effortless Model Compression with Nota AI’s NetsPresso Toolkit
Written on
Introduction to Nota AI’s Compression Toolkit
This review focuses on Nota AI’s NetsPresso Compression Toolkit (NPTK). If you're unfamiliar with this toolkit, a detailed introduction and an overview of its compression techniques are available [here](#).
I was pleasantly surprised by the user-friendliness of Nota’s compression toolkit. Instead of poring over lengthy documentation and tweaking various parameters, I simply uploaded my model to the NetsPresso interface, adjusted a few settings according to my compression objectives, and received a compressed model along with valuable metrics. The structured pruning recommendation feature is particularly advantageous for users lacking a deep theoretical background, allowing them to optimize their models with ease.
My current project involves a semantic segmentation task aimed at extracting biological features from electron microscopy images. One of the models I'm working with is the DeepLab architecture, which I later discovered was not compatible with the compression process due to certain implementation issues.
After reaching out to customer support, I received a prompt and informative response within a day. The support team clarified the issue, corrected the architecture code, confirmed its compatibility with the compression toolkit, and promptly returned the model weights and code to me. I couldn't have asked for a better support experience!
I proceeded to upload my model and opted for structured pruning based on L2 norm criteria.
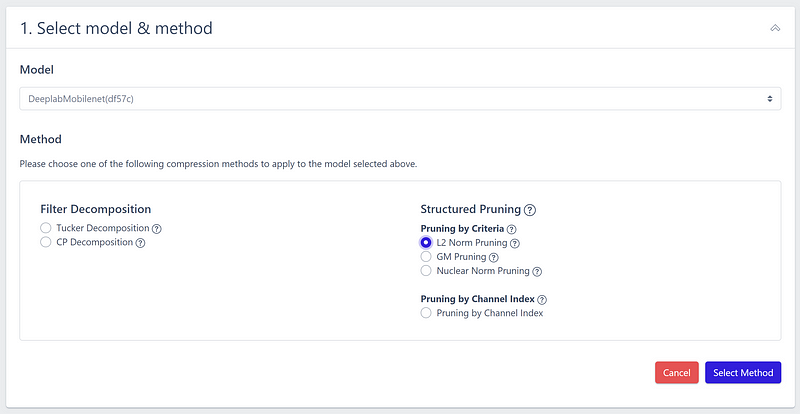
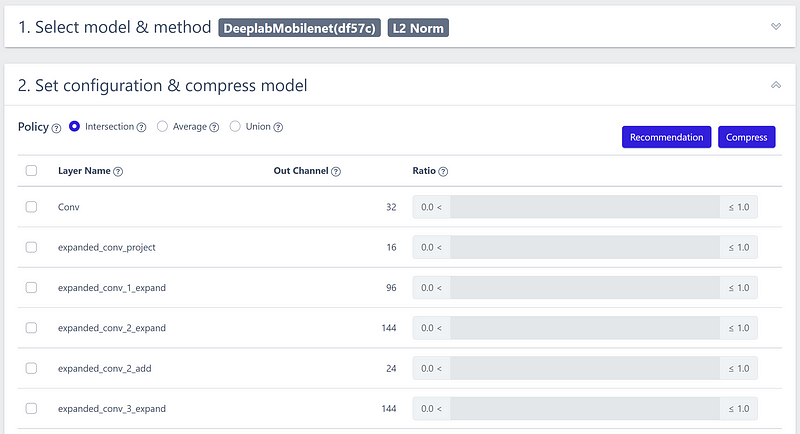
To expedite the model compression, I utilized the “Recommendation” feature to automatically choose the most suitable layers for pruning.
Employing the SLAMP method, I determined an optimal pruning ratio of 75%.
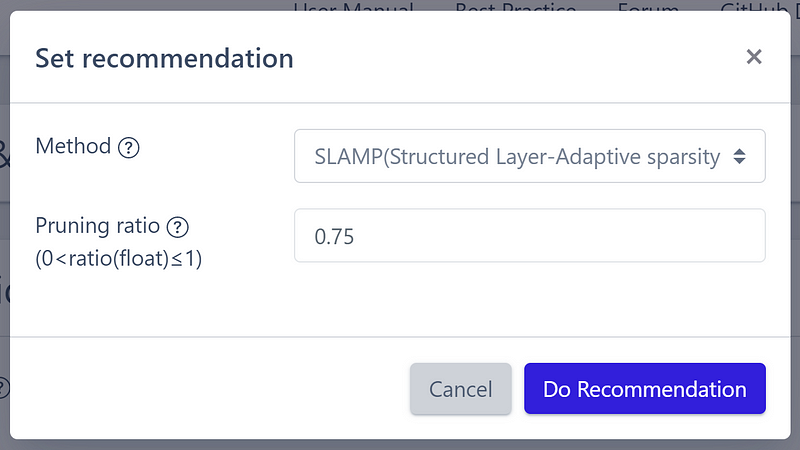
The system automatically configured the best settings for my needs.
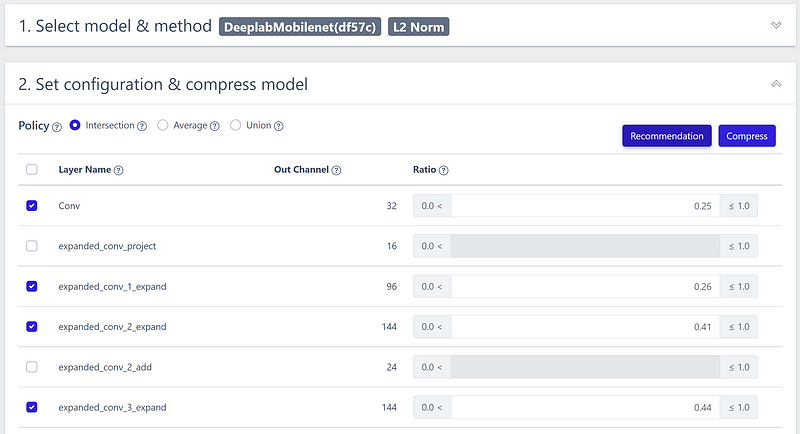
After a few minutes of processing, Nota promptly downloaded the compressed model architecture and presented the compression results. I achieved a remarkable reduction of over five times in storage size and a decrease in trainable parameters by more than seven times!
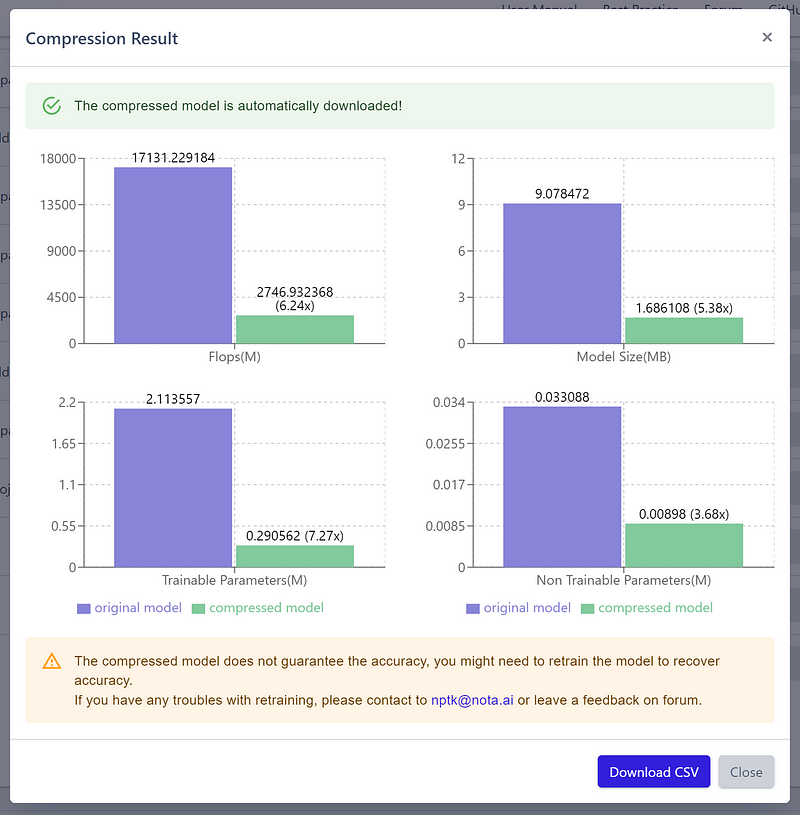
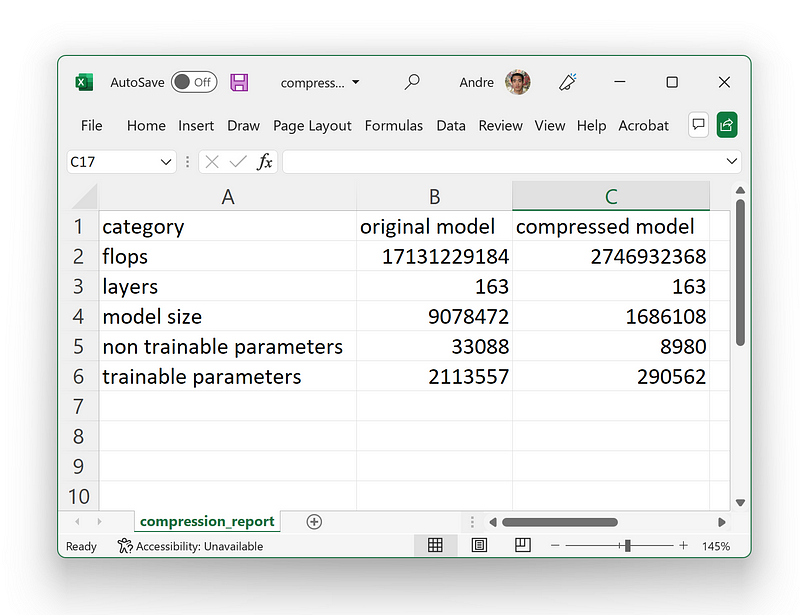
Nota also provided an option to download the compression statistics in a .csv format, making it easy to track the specifics.
After further fine-tuning the dataset, I managed to restore the performance of the compressed model to levels comparable to the original uncompressed version. The NetsPresso toolkit also features well-organized documentation, which I found incredibly helpful for understanding the various compression methods and strategies. The example workflows, such as the VGG19 on CIFAR-100, provided clear guidance on optimal usage.
In the realm of deep learning model compression, effective platforms are rare. Previously, I relied on the TensorFlow Model Optimization library for model optimization. While it is functional in many scenarios, it can be complex and lacks certain compression capabilities. For example, TensorFlow’s pruning does not allow for structured pruning of entire nodes or layers, nor does it let users specify particular pruning criteria or algorithms—features that NPTK offers.
As deep learning applications transition from research environments and high-capacity cloud solutions to smaller devices with limited storage and stringent latency requirements, the importance of model compression grows. Based on my experience, the NetsPresso Compression Toolkit delivers customizable compression outcomes effortlessly, all while providing excellent support.
Exploring the Video Resource
For a more visual understanding of the NetsPresso Compression Toolkit, check out the following video:
This video, titled "Nota AI - NetsPresso Model Searcher Demo," showcases how the toolkit operates, providing a comprehensive overview of its features and functionalities.